

- Introdução
- Imutabilidade e seu impacto real
- Analisando com Big O e benchmarking
- Quando a imutabilidade é um problema real
- Quando a imutabilidade é uma vantagem
- Conclusão
- Referências
Introdução
Se você já ouviu que “programação funcional é mais lenta” ou “usar imutabilidade custa muito em performance”, você não está sozinho. É uma dúvida genuína sobre o paradigmas de programação funcional. Mas será que essa premissa é realmente verdadeira?
Neste artigo, vou explorar a relação entre imutabilidade (um pilar da programação funcional) e performance de código, usando análise de complexidade Big O e benchmarks reais. Se você já leu meu artigo sobre Pensamento Funcional, esse texto é um complemento perfeito para aprofundar seu entendimento sobre as práticas da programação funcional.
Imutabilidade e seu impacto real
Quando falamos sobre imutabilidade, existe um mal-entendido comum: “Se não posso mudar um objeto, preciso criar uma cópia completa cada vez que quero fazer uma alteração”. À primeira vista, isso parece péssimo para a performance, não é?
Imagine um array com 1 milhão de elementos. Se eu quiser mudar apenas um elemento e precisar copiar todo o array, isso seria desastroso para a performance e o uso de memória. Mas aqui está o segredo: as cópias na programação funcional geralmente não são completas!
Os criadores de linguagens e bibliotecas funcionais são engenheiros brilhantes que entendem perfeitamente esse desafio. Por isso, desenvolveram estruturas de dados especiais chamadas estruturas de dados persistentes (ou imutáveis) que são otimizadas para trabalhar com imutabilidade sem penalidades severas de performance.
Estruturas de dados persistentes
Estruturas de dados persistentes são projetadas para preservar versões anteriores quando modificadas, permitindo acesso eficiente tanto à versão antiga quanto à nova.
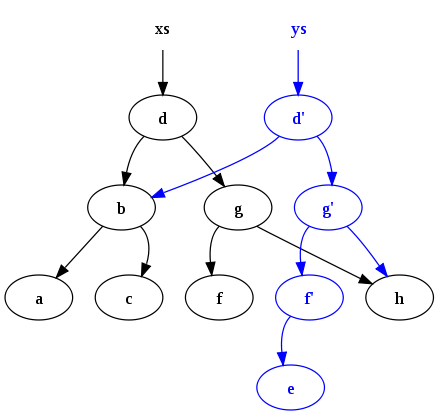
Quando modificamos um nó em uma árvore persistente, criamos uma nova versão da árvore que compartilha a maior parte de sua estrutura com a versão anterior. Apenas os nós afetados pela mudança (e seus ancestrais até a raiz) são copiados. Isso é chamado de path copying ou “cópia de caminho”.
Este princípio se aplica a diversas estruturas de dados imutáveis:
- Listas ligadas persistentes
- Mapas baseados em tries (como os usados em Clojure)
- Vetores persistentes (como RRB-Trees)
- Hash arrays mapped tries (HAMT)
Mas e a memória? Você pode pensar: “Mesmo com compartilhamento estrutural, ainda criamos novas versões o tempo todo. Não vamos esgotar a memória rapidamente?”
Aqui entra outro conceito importante: o coletor de lixo (garbage collector). Quando versões antigas de estruturas não são mais referenciadas pelo seu programa, o coletor de lixo as remove automaticamente da memória. Além disso, compiladores e runtimes modernos aplicam otimizações adicionais que podem eliminar cópias desnecessárias.
Linguagens como Clojure, Scala, Haskell e até mesmo bibliotecas JavaScript como Immutable.js são exemplos notáveis que implementam essas otimizações.
Analisando com Big O e benchmarking
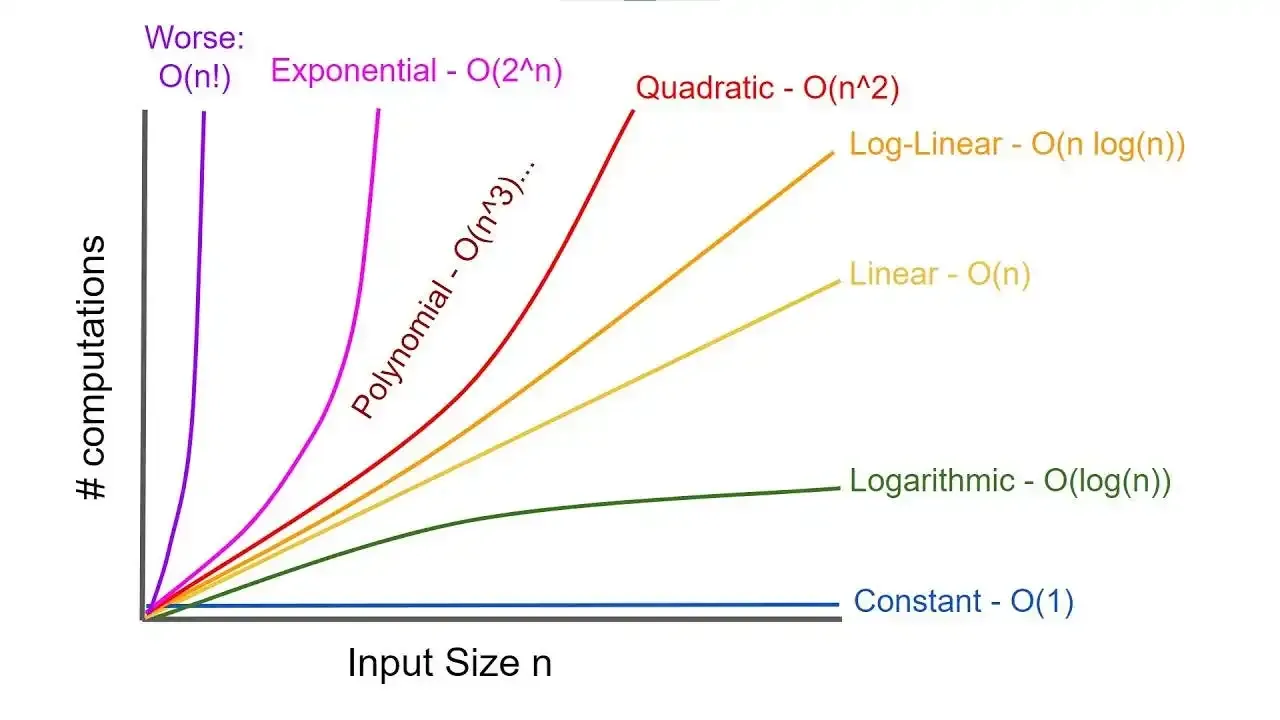
Recomendação: Caso não tenha familiariadade com Big O, recomendo este Tutorial do Geeks ForGeeks sobre sobre Big O Notation, caso já tenha alguma familiariadade e não se lembra, recomendo esta folha de consulta do Neetcode.
Comparando abordagens imperativas e funcionais
Considere a seguinte tarefa: “Dada uma lista de números, quero filtrar os números pares, dobrá-los e então somar tudo.”
Vamos comparar as abordagens imperativa e funcional em Python:
# Abordagem imperativa
def soma_pares_dobrados_imperativa(numeros):
total = 0 # O(1)
for n in numeros: # O(n)
if n % 2 == 0: # Filtra pares em O(1)
total += n * 2 # Dobra e adiciona ao total em O(1)
return total
# Abordagem funcional
def soma_pares_dobrados_funcional(numeros):
pares = filter(lambda x: x % 2 == 0, numeros) # Filtra pares em O(n)
dobrados = map(lambda x: x * 2, pares) # Dobra os pares em O(n)
return sum(dobrados) # Soma tudo em O(n)
Análise de complexidade
A primeira vista, a abordagem imperativa parece mais eficiente porque:
- Realiza todas as operações em um único loop
- Tem complexidade O(n) teórica (O(1) + O(n) + O(1) = O(n))
A abordagem funcional:
- Cria estruturas intermediárias para cada transformação
- Também tem complexidade O(n) teórica com uma constante extra por envolver múltiplos loops (O(n) + O(n) + O(n) = O(3n) => O(n))
Comparando abordagens com análise empírica
Vamos considerar um exemplo mais complexo, onde manipulamos uma coleção de usuários para adicionar um novo status:
def adicionar_status_premium_imperativo(usuarios):
for usuario in usuarios:
if usuario["status"] == "ativo":
usuario["status_premium"] = True
else:
usuario["status_premium"] = False
return usuarios # Retorna a mesma lista, modificada
# Abordagem funcional (imutável)
def adicionar_status_premium_funcional(usuarios):
return [
{**usuario, "status_premium": usuario["status"] == "ativo"}
for usuario in usuarios
] # Retorna uma nova lista com novos objetos
# Vamos medir o tempo de execução de ambas com uma lista maior
import time
# Gerar lista maior para teste
usuarios = [
{"id": i, "status": "ativo" if i % 2 == 0 else "inativo"}
for i in range(1000000) # 1 milhão de usuários
]
# Testar abordagem imperativa
inicio = time.time()
resultado_imp = adicionar_status_premium_imperativo(usuarios.copy())
tempo_imp = time.time() - inicio
# Testar abordagem funcional
inicio = time.time()
resultado_func = adicionar_status_premium_funcional(usuarios)
tempo_func = time.time() - inicio
print(f"Tempo imperativo: {tempo_imp:.6f}s")
print(f"Tempo funcional: {tempo_func:.6f}s")
print(f"Proporção (func/imp): {tempo_func/tempo_imp:.2f}x")
Os resultados mostram que a abordagem imutável é aproximadamente 3-4x (em minha máquina que não tem uma CPU High-end de uso dedicado para processamento intensivo) mais lenta que a mutável para esse caso específico. No entanto, esse overhead diminui significativamente em código otimizado e com implementações mais eficientes de estruturas de dados imutáveis.
O que podemos concluir?
- Sim, há uma diferença - A abordagem imperativa geralmente é mais rápida em operações simples
- A diferença é constante - A proporção se mantém similar conforme a entrada cresce
- Ambas escalam linearmente - As duas abordagens continuam sendo O(n)
- O impacto prático é questionável - Na maioria dos casos de uso, essa diferença de performance é insignificante
Em sistemas reais, outros fatores costumam ter impacto muito maior na performance:
- Acesso a banco de dados
- Operações de rede
- Renderização de UI
- Algoritmos ineficientes (independente do paradigma)
O mais interessante é que, como apontado em discussões sobre o tema, o maior ganho de “performance” muitas vezes não está no desempenho em tempo de execução, mas na “performance do desenvolvedor”. A imutabilidade torna o código significativamente mais fácil de entender e depurar, o que frequentemente leva a um sistema mais rápido na prática, porque os desenvolvedores têm mais tempo para otimizar o código sem serem “inundados por bugs”.
Para mim, o maior aumento de ‘performance’ não está no desempenho em runtime, mas no desempenho do desenvolvedor. Uma das primeiras coisas que aprendi trabalhando em aplicações do mundo real é que a mutabilidade é realmente perigosa e confusa. Perdi muitas horas perseguindo um fluxo de execução tentando descobrir o que estava causando um bug obscuro, quando acabou sendo uma mutação do outro lado do maldito aplicativo!
— Desenvolvedor na discussão “Does immutability hurt performance in JavaScript?
De acordo com essa discussão, a imutabilidade permite um compartilhamento muito extensivo de dados sem consequências reais, algo que seria arriscado em um ambiente mutável.
Quando a imutabilidade é um problema real
Embora o impacto da imutabilidade geralmente seja superestimado, existem cenários onde ela pode representar um gargalo real:
Sistemas com computação numericamente intensiva
Vamos imaginar um cenário de computação gráfica por exemplo, onde precisamos aplicar uma transformação em uma imagem, como isso funciona?
Na prática uma imagem na computação é representada como uma matriz de pixels (ou array), onde cada pixel é representado por um vetor de cores (RGB). Para aplicar uma transformação, como um filtro, precisamos iterar sobre cada pixel e aplicar a transformação desejada.
É certo imaginar que, se tivermos uma imagem de 1920x1080 pixels, isso significa que teremos 2.073.600 pixels para processar. Se cada pixel for representado por um vetor de 3 cores (RGB), teremos 6.220.800 valores para processar.
Se todas as vezes que a imagem for alterada, tivermos que criar uma nova matriz de pixels, isso pode ser extremamente custoso em termos de performance. Por isso, muitas bibliotecas de computação gráfica ou até mesmo de Machine Learning como NumPy e Pandas usam operações mutáveis “in-place” para aplicar transformações, pois, operações repetidas milhões de vezes podem ser até 10x mais lentas com estruturas imutáveis.
Sistemas com restrições de recursos
A muito tempo atrás, quando a memória RAM era extremamente cara, mutabilidade era uma necessidade, no caso, o famoso termo escovar bits (bit brushing) era uma prática comum. Ainda hoje, em sistemas com recursos limitados, como dispositivos IoT, sistemas embarcados e aplicações móveis, essa prática ainda é comum.
Acredito que não seja necessário desenvolver muito sobre o porquê da imutabilidade não ser uma boa ideia no geral para esses sistemas, mas pense um pouco quais são as linguagens de programação que são mais utilizadas para estes sistemas? O que todas elas têm em comum?
Sistemas que possuem Hot paths de alta frequência
Hot pathssão trechos de código que são executados com frequência extrema.
Vamos imaginar uma empresa que possui um bróker de ações, onde existe oferecimento da funcionalidade de Trading (Compra e venda de ações em um curto período de tempo). Nesse cenário, o sistema precisa processar milhões de ordens por segundo, e cada milissegundo conta. Nesse caso, a alocação de novos objetos e a pressão sobre o garbage collector podem ser problemáticas.
Aqui, na realidade o que mais entra em cena é a questão do paralelismo em baixa latência, onde o sistema precisa processar várias ordens simultaneamente, garantindo consistência e integridade dos dados. Consegue imaginar um cenário deste com imutabilidade?
Desenvolvimento de Jogos e aplicações de baixo nível
Este tema está conectado com o tema de Sistemas com computação numericamente intensiva, mas é um pouco mais específico. Em jogos, principalmente os multiplataformas (que rodam em diferentes tipos de hardware), ter um controle eficiente da memória é importantíssimo, já jogou aquele jogo que tem um gráfico mediano mas tem um desempenho horrível? Isso pode ser um sinal de que o jogo não está utilizando a memória de forma eficiente, isto é, está havendo alto reprocessamento de objetos, alocação desnecessária de memória e entre outros problemas os quais a imutabilidade pode e vai causar.
Quando a imutabilidade é uma vantagem
Agora que você viu alguns cenários onde a imutabilidade pode não ser uma boa escolha se você precisa de performance, vamos explorar os cenários onde a imutabilidade realmente brilha e traz benefícios significativos.
Concorrência e sistemas distribuídos
Imagine um sistema onde vários threads estão processando uma lista de usuários. Se essa lista for mutável, um thread pode estar iterando sobre ela enquanto outro a modifica, resultando em Race Conditions, comportamentos inconsistentes e até mesmo crashes. Com dados imutáveis, cada thread trabalha com sua própria Snapshot dos dados, eliminando completamente essa classe de problemas.
# Cenário problemático com dados mutáveis em um ambiente concorrente
usuarios_compartilhados = []
# Thread 1
for usuario in usuarios_compartilhados: # Oops, outro thread pode modificar durante a iteração!
processar_usuario(usuario)
# Thread 2
usuarios_compartilhados.append(novo_usuario) # Isso pode quebrar a iteração do Thread 1!
# Com imutabilidade
# Thread 1
minha_copia_usuarios = usuarios.copy() # Ou melhor, usando estruturas de dados imutáveis
for usuario in minha_copia_usuarios: # Agora estamos seguros!
processar_usuario(usuario)
# Thread 2
usuarios_atualizados = usuarios + [novo_usuario] # Nova versão, sem modificar a original
Em sistemas distribuídos, como aplicações baseadas em microserviços ou bancos de dados distribuídos, a imutabilidade torna-se praticamente um requisito. Esses sistemas frequentemente dependem de logs de eventos imutáveis como fonte única de verdade, permitindo:
- Consistência em sistemas distribuídos: cada nó pode trabalhar com sua própria cópia dos dados sem preocupação com atualizações concorrentes
- Replicação simplificada: é muito mais fácil sincronizar eventos imutáveis do que tentar reconciliar estados mutáveis
Ferramentas como Apache Kafka são construídos com a imutabilidade como princípio fundamental, permitindo sistemas altamente distribuídos, resilientes e escaláveis.
Rastreabilidade e cacheamento
Outro benefício é a capacidade de manter históricos completos e implementar sistemas de cacheamento.
Rastreabilidade e viagem no tempo
Quando seus dados são imutáveis, cada mudança cria uma nova versão, criando naturalmente um histórico de todas as alterações. Isso possibilita:
- Depuração simplificada: você pode “voltar no tempo” e inspecionar exatamente como o estado do seu aplicativo evoluiu
- Auditoria: em aplicações financeiras ou de saúde, onde a auditoria é crítica, cada mudança fica automaticamente registrada
Libraries como Redux para React utilizam esse conceito com seu DevTools, que permite aos desenvolvedores literalmente voltar no tempo para entender como o estado do aplicativo evoluiu:
// Em um ambiente Redux
// Cada ação cria um novo estado imutável
dispatch({ type: "ADICIONAR_ITEM", payload: novoItem });
// Mais tarde, você pode "viajar no tempo" para qualquer estado anterior
// sem afetar o histórico de ações - isso seria impossível com estados mutáveis
Cacheamento eficiente com igualdade referencial
A imutabilidade facilita o cacheamento. Como objetos imutáveis nunca mudam, verificar se um objeto é o mesmo que outro é uma simples comparação de referências:
// Com objetos mutáveis, isto é insuficiente:
cacheAnterior === novoObjeto // Pode ser falso mesmo que o conteúdo seja idêntico, pois em JavaScript
// objetos com os mesmos valores mas criados separadamente têm referências diferentes
// Com imutabilidade, isto funciona perfeitamente:
cacheAnterior === novoObjeto // Se falso, garantidamente algo mudou!
// Se verdadeiro, garantimos que é exatamente o mesmo objeto (não foi modificado)
Isso permite:
- Memoização simplificada: funções como
React.memoouuseMemoem React podem evitar recálculos desnecessários com uma simples verificação de igualdade referencial - Detecção de alterações: sistemas reativos podem saber exatamente o que mudou e recalcular apenas o necessário
Vejamos em React:
// Componente que usa memoização baseada em imutabilidade
const UsuarioCard = React.memo(({ usuario }) => {
// Este componente só será re-renderizado se a referência 'usuario' mudar
return <div>{usuario.nome}</div>
});
// Em algum lugar no componente pai:
const usuarioAtualizado = { ...usuario, ultimoAcesso: new Date() }; // Novo objeto
return <UsuarioCard usuario={usuarioAtualizado} />; // Causa re-renderização
// vs.
usuario.ultimoAcesso = new Date(); // Modificação in-place
return <UsuarioCard usuario={usuario} />; // NÃO causaria re-renderização!
Conclusão
-
A imutabilidade tem um custo, mas esse custo é frequentemente superestimado e geralmente se mantém constante (O(1)) ou linear (O(n)) graças às estruturas de dados persistentes otimizadas.
-
Existem casos específicos onde a mutabilidade é claramente vantajosa: computação numérica intensiva, sistemas com recursos limitados e hot paths de alto desempenho.
-
Existem casos onde a imutabilidade é decisivamente superior: concorrência, sistemas distribuídos, rastreabilidade e cacheamento.
-
A escolha não é binária: muitos sistemas bem-sucedidos combinam abordagens, usando imutabilidade nas camadas de domínio e negócio, e permitindo mutabilidade controlada onde a performance é crítica.
O mais importante é entender que paradigmas são ferramentas. Um bom engenheiro de software sabe quando abraçar a imutabilidade pelos seus benefícios de segurança e previsibilidade, e quando relaxar essa restrição para atender requisitos específicos de performance.
Lembre-se: o algoritmo mais elegante não é útil se não atender aos requisitos de performance do sistema, mas também o código mais rápido não serve se estiver cheio de bugs sutis causados por mutabilidade descontrolada.
Como em muitas coisas na engenharia de software, a resposta para “imutabilidade ou mutabilidade?” é o clássico: “depende”. Agora você tem o conhecimento para tomar essa decisão de forma informada.
Referências
- Persistent Data Structures - Wikipedia
- Persistent Data Structures and Structural Sharing
- Big O Notation - Neetcode
- Immutability Changes Everything (ACM Queue)
- Why Clojure? - Uncle Bob
- Does immutability hurt performance in JavaScript? - Software Engineering Stack Exchange
Espero que tenha gostado do artigo e que ele tenha esclarecido alguns dos mitos e verdades sobre imutabilidade e performance. Se tiver alguma dúvida ou sugestão, deixe um comentário abaixo ou entre em contato comigo pelo LinkedIn.